











以下是官方的介绍:
我们今天发布了稳定视频扩散(Stable Video Diffusion),这是我们基于图像模型稳定扩散(Stable Diffusion)推出的第一个生成式视频基础模型。
这款最先进的生成式AI视频模型现已在研究预览版中推出,它代表了我们在为各种用户创建模型的过程中迈出的重要一步。


通过这一研究版本的发布,我们已在GitHub仓库上公开了稳定视频扩散的代码,运行该模型本地所需的权重可在我们的Hugging Face页面上找到。有关该模型技术能力的更多细节可在我们的研究论文中找到。
适用于各种视频应用
我们的视频模型可以通过在多视角数据集上微调轻松地适应各种下游任务,包括从单个图像生成多视角合成。我们计划开发各种基于此基础模型并对其进行扩展的模型,类似于稳定扩散周围已经形成的生态系统。

来自我们微调过的视频模型的多视角生成示例
此外,从今天开始,您可以在此登记加入我们的等待列表,以访问全新的基于文本到视频界面的网络体验。此工具展示了稳定视频扩散在广告、教育、娱乐等多个行业中的实际应用。
性能具有竞争力
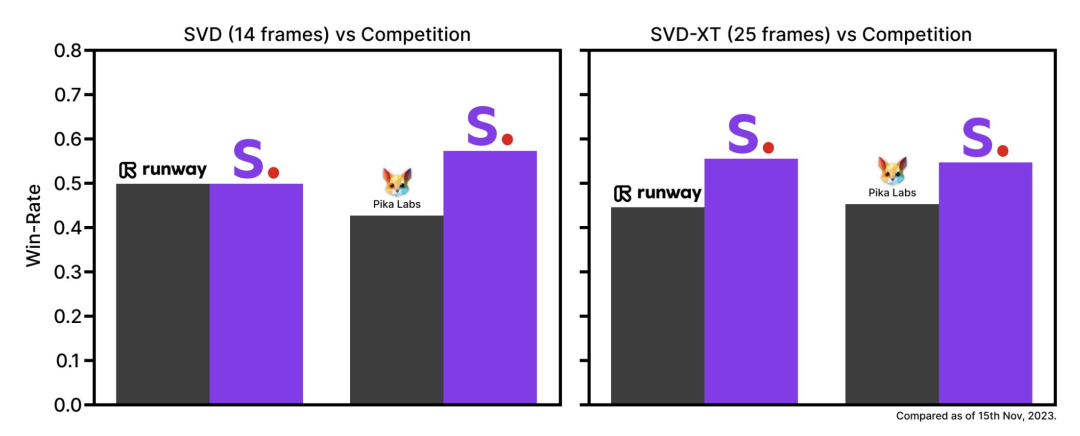
稳定视频扩散以两种图像到视频的模型形式发布,能够以每秒3至30帧的可自定义帧速率生成14和25帧。在最初的基础形式下发布时,通过外部评估,我们发现这些模型在用户偏好研究中超过了领先的封闭模型。
仅用于研究
虽然我们急切地用最新的进展更新我们的模型,并努力结合您的反馈,但我们强调,这个模型在当前阶段并不打算用于实际或商业应用。您对安全性和质量的见解和反馈对于提炼此模型以最终发布是非常重要的。
这与我们在新模式下的以前发布相呼应,我们期待与大家分享完整的发布。

一点看法
从发布的demo视频效果来看,画质上并没有runway和pika好,展示的功能也只是文生视频,至于效果来说目前还没人使用到所以也不清楚。而且好像需要A100的卡才能用,这个根本不是民用显卡的配置。
虽然它号称比runway和pika性能更高,在现在这个阶段Pika和runway已经开始卷可控性和画质了,目前的demo看不出有什么更好的点。如果加上SD的开源生态可能会不一样,但是现在它也还没说要开源
综上所述,可以观察,但是并无惊喜。
不过AI生成视频开始卷了,也就意味着更好的产品一定在路上了。





